

Introduction
Most security teams don't fail because they lack tools - they fail because they're overwhelmed, understaffed, and fighting threats across too many surfaces at once. Managed Extended Detection and Response (MXDR) is built to solve exactly that: a fully managed service that extends detection and response across endpoints, networks, identities, cloud environments, and email, operated by an external team of security experts.
But MXDR is not plug-and-play. Organizations that deploy it without a structured approach often face alert overload, integration failures, and missed threats instead of better security outcomes.
The cybersecurity talent gap has reached nearly 4 million professionals globally, and 59% of security teams are overwhelmed by alert volume. For most mid-market and SMB organizations, building a 24/7 in-house SOC requires 8–12 analysts at an annual cost of $1 million to $4 million - financially prohibitive for many. MXDR bridges that gap by combining advanced detection technology with expert human analysis - provided it's implemented with the right foundation in place.
This guide covers what MXDR is, why security operations teams depend on it, and how to implement it without the missteps that most commonly derail success.
Overview
- Managed XDR combines XDR technology with 24/7 human expertise, extending detection across your entire attack surface
- Successful implementation follows five steps: assess your posture, define scope, integrate data sources, tune detections, and establish governance
- Alert fatigue, integration gaps, and over-reliance on automation are the most common reasons MXDR underperforms
- Choose SOC 2 certified providers with proven experience, 24/7 coverage, and compatibility with your existing stack
- MXDR isn't right for every organization; knowing its service boundaries prevents costly gaps in coverage
What Is Managed XDR?
Managed XDR (MXDR) combines Extended Detection and Response technology with outsourced security expertise. A provider handles the full stack - deployment, integration, tuning, monitoring, and response - on behalf of the client organization.
The result is unified visibility across all security layers - endpoint, network, cloud, identity, and email - with continuous threat monitoring, investigation, and response. Organizations get enterprise-grade detection and 24/7 coverage through a predictable subscription cost, without building and staffing an in-house SOC.
Distinguishing MXDR from related services:
- XDR is the underlying technology platform - it correlates telemetry across security domains but requires in-house staff to operate
- MDR predates XDR and relies on varied detection tools, with a historical focus on endpoints rather than full-stack coverage
- MXDR runs on an XDR engine, enabling integrated response actions across cloud, identity, network, and endpoints in a single managed service

SOC 2 Type 2 certified providers like Cybriant deliver this through platforms such as SentinelOne and Google SecOps, paired with experienced analysts who validate alerts, investigate threats, and guide remediation - making enterprise-grade security accessible to organizations of any size.
Why Security Operations Teams Are Turning to Managed XDR
The shift to MXDR is driven by structural workforce challenges and operational realities that make traditional in-house SOCs unsustainable for most organizations.
Critical skills shortage: The global cybersecurity workforce gap reached 3,999,964 in 2023, a 12.6% year-over-year increase, with 67% of organizations reporting staff shortages. Additionally, 59% of organizations report critical skills gaps on their security teams. The median annual wage for a U.S. Information Security Analyst is $124,910, making it financially prohibitive to staff round-the-clock operations.
Operational burnout: 71% of SOC analysts report experiencing burnout, and 64% are considering leaving their role within one year. Alert fatigue compounds the problem:
- 59% of teams deal with too many alerts; 55% face excessive false positives (Splunk State of Security)
- An estimated 46% of alerts are false positives
- 42% of alerts go completely uninvestigated
What happens without MXDR: Siloed tools generate disconnected alerts. Mean time to detect (MTTD) and mean time to respond (MTTR) increase. Threats persist undetected across security layers. Most organizations simply cannot hire, train, and retain the staff needed to close these gaps internally.
MXDR delivers enterprise-grade security at scale: For SMBs and mid-market enterprises, MXDR delivers enterprise-grade security capabilities without the cost of building and staffing a 24/7 in-house SOC. The XDR market is projected to grow from $7.92 billion in 2025 to $30.86 billion by 2030, with SMEs representing the fastest-growing segment at a 33.1% CAGR. That adoption rate reflects a straightforward reality: advanced protection no longer requires an enterprise-sized budget.
How to Implement Managed XDR in Your Security Operations
MXDR implementation moves through five stages: readiness and scoping, data source integration, detection tuning, live monitoring handoff, and continuous improvement. Skip any one of them and you're likely to discover the gap during an incident - not before it.
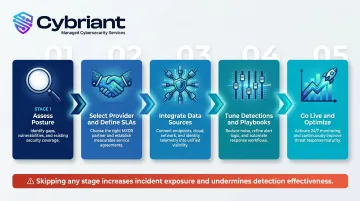
Step 1: Assess Your Current Security Posture and Define Scope
Conduct a comprehensive security posture assessment before any deployment. This assessment should:
- Inventory all assets: Catalog endpoints, servers, cloud workloads, identities, SaaS applications, and network segments
- Document existing tools: List all security tools and log sources currently in use
- Identify coverage gaps: Determine where visibility is incomplete or detection is weak
- Establish baseline metrics: Measure current MTTD, MTTR, and alert volume for future comparison
Approximately 79% of organizations report widening asset visibility gaps, forcing security teams to rely on guesswork during incident response. An MXDR provider cannot protect assets it cannot see. Follow frameworks like NIST CSF 2.0 (Asset Management ID.AM-01 through ID.AM-08) and CIS Controls v8.1 (Controls 1 and 2) for enterprise asset and software inventory.
Define scope clearly: Establish what attack surface the MXDR provider will cover and what remains the responsibility of internal teams. Scope ambiguity is one of the leading causes of failed deployments. Document which environments, applications, and data sources fall within MXDR coverage, and communicate any exclusions or limitations upfront.
Step 2: Select the Right Managed XDR Provider and Establish SLAs
Evaluate providers against clear, objective criteria:
- Coverage depth: Confirm the provider monitors across endpoints, network, cloud, identity, and email - not just endpoints
- Technology compatibility: Ensure the platform integrates with your existing security stack
- 24/7 SOC staffing: Verify true around-the-clock analyst coverage, not just automated alerts
- Proven incident response capabilities: Review case studies and references from similar organizations
- Compliance certifications: Look for SOC 2 Type 2, ISO 27001, HIPAA, PCI DSS, and other relevant frameworks
- Transparent SLAs: Define and document expected response times, escalation procedures, and reporting cadence
Cybriant, for example, holds SOC 2 Type 2 certification and runs 24/7 analyst-staffed monitoring on SentinelOne and Google SecOps - covering endpoints, identities, and cloud environments from a single platform.
Critical SLA considerations: Vague SLAs lead to accountability gaps when incidents occur. Before signing, document:
- Response time commitments for different alert severities
- Escalation protocols and contact requirements
- Reporting deliverables and frequency
- Defined responsibilities for remediation and patching
Gartner warns against over-relying on SLAs if internal teams cannot consume the outputs: focus on operational KPIs and tested response playbooks.
Step 3: Integrate Data Sources and Connect Your Security Stack
Execute the technical integration phase methodically:
- Deploy sensors or agents on endpoints to capture telemetry
- Connect cloud platforms via APIs (AWS, Azure, GCP) to monitor workload activity
- Configure log forwarding from firewalls, identity systems, and network devices
- Format log data to meet the MXDR platform's ingestion requirements
Modern MXDR providers using API-based integrations can connect high-priority tools in hours to days. However, legacy systems often lack the flexibility required to seamlessly integrate, resulting in data silos that limit comprehensive threat analysis. Budget and deployment complexity are the most frequently cited barriers to XDR adoption.
Two integration risks deserve attention before go-live:
- Legacy systems: On-premises infrastructure, custom applications, and heterogeneous endpoint fleets increase integration time and cost. Identify these during scoping - some will require custom middleware or connector code.
- Data noise: 41% of organizations report highly fragmented data, and 61% rely on manual approaches to integrate security controls. Prioritize high-signal sources aligned to your threat model rather than maximizing volume.
Step 4: Tune Detection Rules and Establish Response Playbooks
Work with the provider to configure detection logic specific to your environment and threat profile:
- Suppress known false positives: Identify and filter out noise sources that generate benign alerts
- Set alert thresholds: Align sensitivity to your risk tolerance and operational capacity
- Map detections to MITRE ATT&CK: 74% of organizations use the ATT&CK Matrix.pdf>) to track adversary tactics and assess coverage gaps; ensure your MXDR provider does the same
The cost of poor tuning: 73% of organizations list false positives as their number one threat detection challenge. False positive rates in enterprise SOCs frequently exceed 50%, sometimes reaching 80%. The Ponemon Institute estimates the cost of time wasted responding to erroneous alerts at $1.27 million annually.
Define response playbooks before going live. Two categories need clear boundaries:
- Provider-autonomous actions: Endpoint isolation, IP blocking, quarantine
- Internal approval required: Shutting down business-critical systems, blocking executive access
Document escalation contacts for each critical system. Playbooks must be tested before an incident - not written during one.
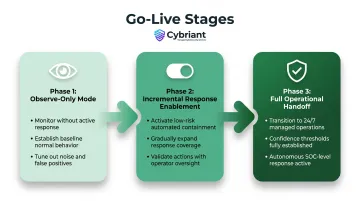
Step 5: Go Live, Measure, and Continuously Optimize
Execute a phased go-live rather than a full cutover:
- Observe-only mode: Begin monitoring without active response to baseline normal behavior and tune out noise
- Incremental response enablement: Activate containment actions gradually, starting with low-risk automated responses
- Full operational handoff: Transition to 24/7 managed operations once confidence is established
Track key metrics from day one:
- Alert volume (total alerts generated and actionable alerts escalated)
- False positive rate
- Mean time to detect (MTTD) and mean time to respond (MTTR)
- SLA compliance (response times met vs. committed)
- Percentage of incidents resolved autonomously vs. escalated


